Pandas는 데이터 분석을 위한 라이브러리로, Numpy와 함께 데이터 분석에 있어서 가장 기본이 되는 라이브러리입니다. Pandas는 데이터를 효과적으로 처리할 수 있는 다양한 기능을 제공합니다. 이번 챕터에서는 Pandas의 기본적인 사용법을 알아보겠습니다.
1.1 Pandas의 데이터 구조
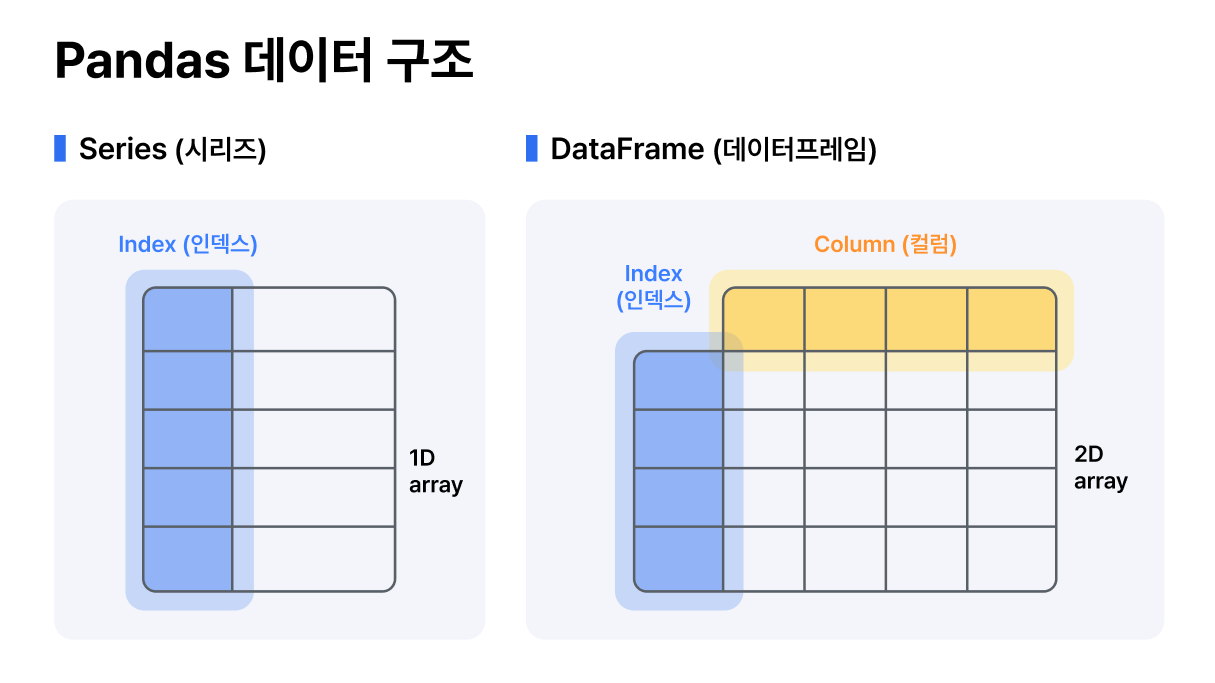
Pandas는 크게 Series와 DataFrame 두 가지 데이터 구조를 제공합니다. Series는 1차원 배열이고, DataFrame은 2차원 배열입니다. Series와 DataFrame은 Numpy 배열과 유사하지만, 인덱스를 가지고 있어 데이터를 더 효율적으로 처리할 수 있습니다.
1.2 Pandas Series
Pandas Series는 1차원 배열입니다. Series는 인덱스를 가지고 있어 데이터를 더 효율적으로 처리할 수 있습니다. 이 인덱스는 데이터의 레이블 역할을 하며, 데이터를 빠르게 검색할 수 있습니다.
import pandas as pd
data = [1, 2, 3, 4, 5]
s = pd.Series(data)
print(s)
print(s[0])
print(s[1:4])
아래는 Series의 인덱스를 지정하는 예제입니다.
import pandas as pd
data = [1, 2, 3, 4, 5]
index = ['a', 'b', 'c', 'd', 'e']
s = pd.Series(data, index=index)
print(s)
print(s['a'])
print(s['b':'d'])
# print(s[0]) # 이 방식도 가능합니다.
인덱스를 지정하지 않으면 0부터 시작하는 정수 인덱스가 자동으로 생성됩니다. 지정을 하면 해당 인덱스로 데이터를 조회할 수 있습니다. 이렇게 지정되지 않았을 때 0부터 시작하는 정수 인덱스를 묵시적 인덱스라고 합니다. 또한 인덱스를 지정하여 데이터를 조회할 때에는 명시적 인덱스라고 합니다.
시리즈와 스칼라는 아래와 같이 연산 됩니다.
import pandas as pd
data = [1, 2, 3, 4, 5]
s = pd.Series(data)
print(s + 10)
print(s * 10)
import pandas as pd
from pyodide.http import open_url
data = open_url('https://paullab.co.kr/stock.html')
df = pd.read_html(data)
df[0] # 0, 1, 2 등을 차례로 넣어보세요.
위니북스에서만 open_url 함수를 사용하고 colab에서는 더 간단한 코드로 작성할 수 있습니다. 아래 코드는 colab에서 사용하는 코드입니다.
import pandas as pddf = pd.read_html('https://paullab.co.kr/stock.html')df[0] # 0, 1, 2 등을 차례로 넣어보세요.
import pandas as pddf = pd.read_html('https://paullab.co.kr/stock.html')df[0] # 0, 1, 2 등을 차례로 넣어보세요.
여기에서 준비한 데이터가 아니고 웹에 있는 데이터라면 아래처럼 불러와서 실행할 수 있습니다. 위키백과에서 대한민국의 인구 데이터를 불러오는 예제입니다. https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EC%9D%B8%EA%B5%AC는 https://ko.wikipedia.org/wiki/대한민국의_인구입니다. 한글을 넣으면 애러가 발생하여 URL 인코딩이 필요합니다.
import pandas as pddf = pd.read_html('https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EC%9D%B8%EA%B5%AC')df # df[0], df[1], df[2] 등을 차례로 넣어보세요.# df[0]['2020']# df[0]['2020'].to_csv('test.csv')# df[0]['2020'].to_json('test2.json')# df[0]['2020'].to_html('test3.html')# df = pd.read_html('test3.html')# df
import pandas as pddf = pd.read_html('https://ko.wikipedia.org/wiki/%EB%8C%80%ED%95%9C%EB%AF%BC%EA%B5%AD%EC%9D%98_%EC%9D%B8%EA%B5%AC')df # df[0], df[1], df[2] 등을 차례로 넣어보세요.# df[0]['2020']# df[0]['2020'].to_csv('test.csv')# df[0]['2020'].to_json('test2.json')# df[0]['2020'].to_html('test3.html')# df = pd.read_html('test3.html')# df
colab에서 함께 실습할만한 코드를 몇 개 더 추가하였습니다.
1.5 데이터 저장하기
Pandas는 데이터를 다양한 형식으로 저장할 수 있습니다. CSV, Excel, SQL, JSON 등 다양한 형식으로 저장할 수 있습니다. 아래는 DataFrame을 CSV 파일로 저장하는 예제입니다. 위니북스에서는 파일 저장 기능이 제한되어 있어, 해당 코드를 실행하고 싶다면 colab에서 실행해주세요.
열을 선택하는 방법은 아래와 같습니다. df['name']와 같이 하나의 데이터를 선택하거나 df[['name', 'age']]와 같이 2개 이상의 데이터를 선택할 수 있습니다.
df['name']
df[['name', 'age']]
# df[['age', 'height']].median() # 이렇게도 사용할 수 있습니다.
출처: Pandas 공식 문서
행을 선택하는 방법은 아래와 같습니다. df.loc[0]와 df.iloc[0]는 같은 결과를 반환합니다. 다만 loc는 사용자가 입력한 명시적인 인덱스를 사용하고, iloc는 자동으로 할당된 묵시적 인덱스를 사용합니다. 사용자가 입력한 인덱스가 없을 경우 명시적 인덱스도 0부터 시작하는 정수 인덱스와 같은 결과를 반환합니다.
Pandas는 데이터를 조작하고 변환하는 다양한 기능을 제공합니다. 가장 기본적인 데이터 조작 방법들을 살펴보겠습니다.
1.7.1 컬럼 조작
컬럼을 생성하고 삭제하는 방법을 살펴보겠습니다.
import pandas as pd
# 샘플 데이터 생성
data = {
'name': ['John', 'Anna', 'Peter', 'Linda'],
'age': [25, 36, 29, 24],
'city': ['New York', 'Paris', 'Berlin', 'London']
}
df = pd.DataFrame(data)
df
새로운 컬럼을 추가하거나, 기존 컬럼의 값을 수정할 수 있습니다.
# 새로운 컬럼 추가
df['age_group'] = ['20대', '30대', '20대', '20대']
# 컬럼 값 수정
df['age'] = df['age'] + 1
# 여러 컬럼을 사용한 새로운 컬럼 생성
df['info'] = df['name'] + ' from ' + df['city']
df
drop을 사용하면 컬럼을 삭제할 수 있습니다.
# 컬럼 삭제
df = df.drop('info', axis=1)
df
1.7.2 결측치 처리
결측치는 데이터에 값이 없는 경우를 의미합니다. 결측치는 데이터 분석에 있어서 문제가 될 수 있으므로, 적절한 방법으로 처리해야 합니다. Pandas는 결측치를 확인하고 제거하거나 채우는 다양한 기능을 제공합니다.
import pandas as pd
# 결측치가 있는 데이터 생성
data = {
'name': ['John', 'Anna', None, 'Linda'],
'age': [25, None, 29, 24],
'city': ['New York', 'Paris', 'Berlin', None]
}
df = pd.DataFrame(data)
# 결측치 확인
print("결측치 확인:")
print(df.isnull().sum())
df
결측치를 제거하거나 채울 수 있습니다. 이 때 원본을 변경하려면 df.dropna(inplace=True)를 사용하면 됩니다. 여기서는 원본을 변경하지 않고 결과만 출력하도록 하겠습니다.
# 결측치 제거
print("결측치 제거:")
df.dropna()
결측치를 채우는 방법은 다양합니다. 평균값, 중앙값, 최빈값 등으로 채울 수 있습니다. 여기서는 평균값으로 채우는 예제를 살펴보겠습니다.
# 복합 조건 (AND)
print("30세 이상이고 Paris에 사는 사람:")
df[(df['age'] >= 30) & (df['city'] == 'Paris')]
# 복합 조건 (OR)
print("Paris나 London에 사는 사람:")
df[(df['city'] == 'London') | (df['city'] == 'Paris')]
1.8.2 query 함수 사용
query 함수를 사용하면 SQL 쿼리처럼 데이터를 필터링할 수 있습니다.
# query 함수를 사용한 필터링
print("salary가 50000 이상인 사람:")
df.query('salary >= 50000')
print("Paris에 살고 30세 이상인 사람:")
df.query('city == "Paris" and age >= 30')
조금 더 복잡한 조건을 사용해보도록 하겠습니다. 이렇게 복잡한 조건은 query 함수를 사용하는 것이 더 편리합니다.
import pandas as pd
# 더 많은 정보를 가진 샘플 데이터 생성
data = {
'name': ['John', 'Anna', 'Peter', 'Linda', 'Tom', 'Lisa', 'Sarah', 'Mike'],
'department': ['IT', 'HR', 'IT', 'HR', 'IT', 'Marketing', 'Marketing', 'HR'],
'age': [25, 36, 29, 24, 32, 27, 31, 28],
'salary': [50000, 60000, 45000, 55000, 65000, 52000, 58000, 51000],
'experience': [2, 8, 4, 3, 6, 4, 5, 3]
}
df = pd.DataFrame(data)
df
# 복잡한 조건 조합
print("(IT 부서이면서 급여 6만 이상) 또는 (HR 부서이면서 경력 5년 이상)인 직원:")
df.query('(department == "IT" and salary >= 60000) or (department == "HR" and experience >= 5)')
1.9 데이터 그룹화와 집계
그룹화는 데이터를 특정 기준에 따라 묶어서 분석하는 것입니다. groupby 함수를 사용하여 데이터를 그룹화할 수 있습니다.
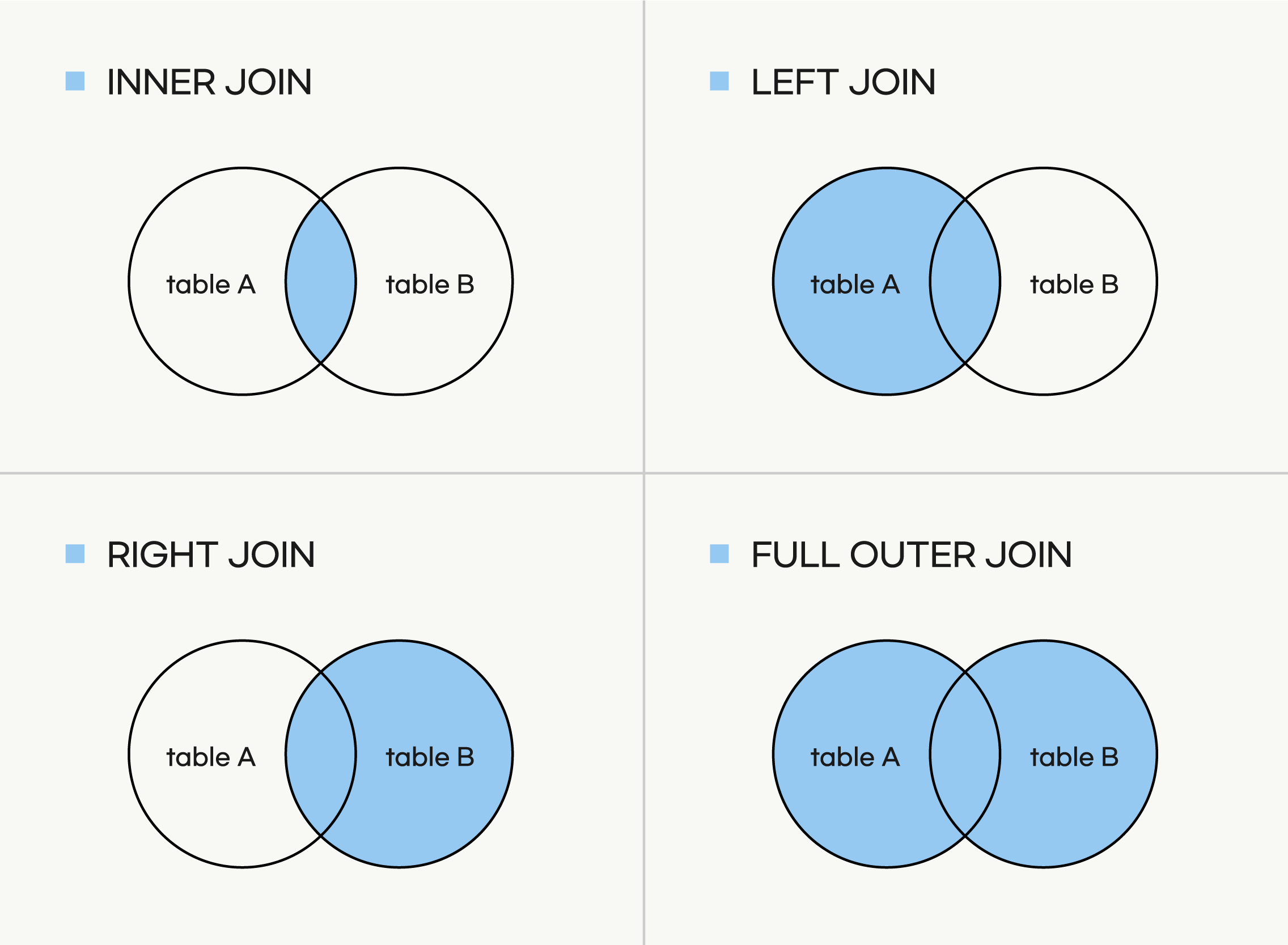
join으로 데이터를 결합할 때에는 인덱스를 기준으로 결합합니다. 이 때, 두 데이터프레임의 인덱스가 일치해야 합니다.
데이터 결합 방법 선택 기준
concat: 단순히 데이터를 이어붙일 때
merge: 특정 컬럼을 기준으로 데이터를 결합할 때
join: 인덱스를 기준으로 데이터를 결합할 때
각각의 결합 방법은 상황에 따라 장단점이 있으므로, 데이터의 구조와 결합 목적에 따라 적절한 방법을 선택해야 합니다.
1.13 데이터 정렬
네, Pandas의 데이터 정렬 파트를 작성하겠습니다.
1.13 데이터 정렬
Pandas에서는 sort_values()와 sort_index() 함수를 사용하여 데이터를 정렬할 수 있습니다. 단일 또는 여러 컬럼을 기준으로 오름차순이나 내림차순 정렬이 가능합니다. 옵션으로는 ascending을 사용하여 오름차순 또는 내림차순을 지정할 수 있습니다.
import pandas as pd
# 샘플 데이터 생성
data = {
'name': ['John', 'Anna', 'Peter', 'Linda', 'Tom'],
'age': [25, 36, 29, 24, 32],
'salary': [50000, 60000, 45000, 55000, 65000]
}
df = pd.DataFrame(data)
df
# 나이를 기준으로 오름차순 정렬
print("나이 기준 오름차순:")
print(df.sort_values('age'))
# 급여를 기준으로 내림차순 정렬
print("급여 기준 내림차순:")
print(df.sort_values('salary', ascending=False))
# 여러 컬럼 기준으로 정렬
print("나이(오름차순)와 급여(내림차순) 기준:")
print(df.sort_values(['age', 'salary'], ascending=[True, False]))
# 인덱스 기준으로 정렬
print("인덱스 기준 정렬:")
print(df.sort_index())