리스트
1. 리스트(List)란?
리스트는 파이썬에서 제공하는 가변적(mutable)이고, 순서가 있는 시퀀스 자료형입니다. 위치의 특성을 가지고 있어 정렬할수 있으며, 가변적이라는 특성 때문에 리스트 내의 원소들은 생성 후에도 변경, 추가, 삭제가 가능합니다. (디렉터리에서 파일리스트, 회사에서 직원리스트, 메일함의 이메일 목록 등)
리스트가 왜 필요할까요?
100명의 성적을 채점하기 위해서 지금까지 배웠던 지식으로는 100개의 변수를 만들어야 했습니다. x1, x2, x3…그것을 쉽게 구현한 것이 리스트라고 생각하시면 됩니다. 이를 배열이라고 하기도합니다.
1.1 리스트 생성
리스트를 생성하는 방법 역시 간단합니다. 대괄호([]) 안에 쉼표(,)로 구분된 데이터들을 넣으면 됩니다.
x = [1, 2, 3] #CSV 파일과 비슷 ,
y = ['apple', 'banana', 'cherry']
z = [1, [2], 3] in [2]x = [1, 2, 3] #CSV 파일과 비슷 ,
y = ['apple', 'banana', 'cherry']
z = [1, [2], 3] in [2]리스트는 문자열뿐만 아니라 다양한 데이터 타입을 포함할 수 있습니다. 심지어 리스트 내부에 또 다른 리스트를 넣는 것도 가능합니다.
이렇게 사용하게 되면 1에는 0, 2에는 1, 3에는 2 / apple에는 0, banana에는 1, cherry는 2라는 주소값이 붙게됩니다. 이는 시퀀스형의 기본입니다. 왜 0부터 시작할까요? 이진수 관점에서 메모리를 절약할수 있다는 장점이 있습니다.
len을 사용하면 리스트안에 몇개의 데이터가 있는지 확인할 수 있습니다. 이는 데이터 검증할때 매우 유용합니다.
print(len(x))
print(len(y))print(len(x))
print(len(y))리스트 안에 여러 종류의 데이터를 혼합하여 저장할 수도 있습니다. 다만 일관된 데이터 처리를 위해 이렇게 혼합해 데이터를 넣는 것을 권장하지 않습니다.
리스트 내부에 저장된 각 데이터를 "항목" 또는 "원소"라고 부릅니다. 위의 z 리스트에는 총 5개의 항목이 있습니다. 리스트는 콤마 사이에 공백을 병합합니다. 아래와 같은 형태가 가능합니다.
아래와 같이 마지막에 콤마를 넣는 경우도 많습니다.
리스트는 순서가 있으므로, 인덱싱을 통해 각 항목에 접근할 수 있습니다. 인덱스는 0부터 시작하며, 첫 번째 항목은 z[0], 두 번째 항목은 z[1]로 접근할 수 있습니다.
# 출력 결과
1# 출력 결과
1리스트는 데이터의 집합을 효과적으로 관리할 수 있는 중요한 자료형입니다. 데이터를 순서대로 저장하고, 필요할 때 쉽게 접근하거나 수정할 수 있으므로 많은 프로그램에서 활용됩니다.
리스트는 사실 고정된 크기가 없습니다. 그러나 존재하지 않는것이 수행이 된다면 나중에 문제가 생길수 있습니다. 가상의 정보가 생성이 된다던가 정보가 꼬일수 있기 때문에 보통은 에러가 발생이됩니다. 그래서 보통 파이썬은 에러를 보고하며, 이를 가능하게 하기 위해서 append() 같은 메서드를 사용합니다.
1.2 리스트의 수정 및 다차원 리스트
파이썬의 리스트는 항목의 변경이 가능하며, 다양한 자료형을 함께 담을 수 있습니다. 더 나아가, 리스트 안에 또 다른 리스트를 담아서 다차원 리스트를 구성할 수도 있습니다.
데이터 분석과 같은 분야에서는 이러한 다차원 리스트를 이용하여 행렬을 표현하기도 합니다.
1.2.1 리스트의 항목 변경하기
리스트는 항목의 변경이 가능합니다. 단순히 인덱싱을 이용하여 값을 할당하는 것만으로 리스트의 특정 항목을 변경할 수 있습니다.
이 코드는 리스트 a의 첫 번째 항목을 10000으로 변경합니다.
1.2.2 문자열은 변경이 불가능하다(immutable)
리스트와는 달리, 문자열은 불변(immutable)입니다. 따라서 문자열의 특정 문자를 변경하는 것은 불가능합니다.
# 출력
TypeError: 'str' object does not support item assignment# 출력
TypeError: 'str' object does not support item assignment위의 코드에서 s[0]은 문자열 s의 첫 번째 문자를 의미하며, 이 값은 'l'입니다. 그러나, s[0] = 'k'를 실행하려고 하면 문자열의 변경은 지원되지 않기 때문에 에러가 발생합니다.
문자열은 한번 생성되면 그 내용을 변경할 수 없습니다. 만약 문자열의 내용을 변경하고 싶다면, 새로운 문자열을 생성해야 합니다.
1.2.3 다차원 리스트
리스트는 다양한 자료형을 담을 수 있기 때문에, 리스트 안에 리스트를 넣어 다차원 리스트를 만들 수 있습니다.
위의 코드에서 b[1][2]는 b 리스트의 두 번째 리스트 항목의 세 번째 값을 의미하며, 이 값은 3입니다.
2. 리스트 연산
2.1 덧셈과 곱셈 연산
이전에 배웠던 문자열과 마찬가지로 리스트에서도 덧셈과 곱셈 연산이 가능합니다. 덧셈은 두 리스트를 연결합니다.
이러한 덧셈은 __add__에 구현이 되어 있기 때문에 가능한 것입니다. __add__에 요소마다 더하는 것으로 구현이 되어 있었다면 [2, 4, 6]을 출력했을 것입니다. 실제로 아래 덧셈은 요소마다 더해지게 되어 있습니다.
곱셈은 리스트를 여러 번 반복합니다.
다만 곱셈은 다음과 같은 사항에 주의해야 합니다.
[1000, 2, 3, 1, 2, 3, 1, 2, 3][1000, 2, 3, 1, 2, 3, 1, 2, 3]위와 같이 중첩되지 않은 리스트의 곱셈은 값이 하나가 변경이 되어도 다른 값들이 변경이 되지 않습니다.
[[1, 2, 3, 1, 2, 3], [1, 2, 3, 1, 2, 3]]
136783650416896, 136783650416896
[[10000, 2, 3, 1, 2, 3], [10000, 2, 3, 1, 2, 3]][[1, 2, 3, 1, 2, 3], [1, 2, 3, 1, 2, 3]]
136783650416896, 136783650416896
[[10000, 2, 3, 1, 2, 3], [10000, 2, 3, 1, 2, 3]]위 코드에서 복사는 제대로 이뤄진 것을 볼 수 있습니다. 다만 이렇게 복사된 것이 id를 확인해보면 같은 id라는 것을 확인할 수 있습니다.
중첩된 리스트가 아닌 경우에는 복사된 리스트가 연결되는 것이기 때문에 단일 요소의 수정이 전체에 영향을 미치게 됩니다.
2.2 리스트 인덱싱
리스트도 문자열처럼 순서가 있어 인덱싱을 통해 각 항목에 접근할 수 있습니다. 인덱스는 0부터 시작하며, 리스트의 마지막 항목의 인덱스는 -1입니다. 그러나 실제 파이썬 구현 레벨에서 보면 음수 인덱싱은 실제로는 len(list) - 1로 계산됩니다. 따라서 모든 음수 인덱싱은 양수로 전환되어 처리됩니다.
리스트는 문자열과 마찬가지로 0부터 인덱싱을 시작합니다. 순서가 있는 시퀀스형 자료형의 공통적인 특징입니다.
범위를 넘어가는 인덱스로 값을 호출하려면 에러가 발생합니다. 에러명은 IndexError 이며, 리스트에 인덱스가 범위를 벗어났다는 것을 나타냅니다.
2.3 리스트 슬라이싱
리스트의 일부분을 추출하고 싶을 때에는 인덱스를 사용하여 잘라낼 수 있습니다.
2.3.1 슬라이싱
슬라이싱은 [start:stop:step] 형태로 사용하며, 마찬가지로 step은 기본적으로 1이며 생략할 수 있습니다.
2.3.2 다양한 슬라이싱 형태 알아보기
문자열과 같이 다양한 형태의 슬라이싱이 사용가능합니다. 맨 아래 예제처럼 슬라이싱을 2번 또는 n번 사용하여 값을 반환하는 것도 가능합니다.
2.3.3 슬라이싱은 에러가 발생하지 않는다
리스트의 슬라이싱은 범위가 넘어가더라도 오류를 발생시키지 않습니다. 이는 안정적인 코드 작성을 위한 특징입니다.
3. 리스트의 구조 및 특징
리스트가 어떻게 동작하는지 대략적으로 알아보았으니 이제 리스트의 상세 구조 및 특징을 면밀히 살펴보도록 하겠습니다.
3.1 메모리 구조
파이썬의 리스트는 동적 배열(dynamic array) 형태로 구현되어 있습니다. 리스트 안에 저장된 값은 연속된 메모리 공간이 아니지만, 이 값을 저장하는 주소는 연속된 메모리 공간입니다. 이러한 구조 때문에 데이터에 접근하는 속도는 O(1)입니다. O(1)은 빅오 일이라고 읽으며 최악의 경우에도 한 번에 접근이 가능하다는 의미입니다.
리스트의 각 원소는 참조를 통해 다양한 위치에 저장된 객체를 가리킵니다. 이 때문에 리스트는 다양한 타입의 데이터를 동시에 저장할 수 있으며, 심지어 자기 자신을 가리킬 수도 있습니다.
l = [1, 2, 3]
l.append(l)
ll = [1, 2, 3]
l.append(l)
l파이썬에서 모든 것은 객체로 취급됩니다. 리스트는 이 객체들의 참조를 저장하는 컨테이너로, 각 요소는 실제 데이터 값이 아닌 해당 객체를 참조하는 주소를 저장합니다.
3.1.1 파이썬의 메모리 구조
다음과 같은 리스트를 예로 들어보겠습니다.
my_list = [1, 2, 'apple', 3.14]my_list = [1, 2, 'apple', 3.14]이 리스트의 메모리 구조는 다음과 같습니다.
1,2,'apple',3.14는 각각 다른 메모리 위치에 저장된 객체입니다.my_list는 이러한 객체들의 참조(메모리 주소)를 저장하는 배열입니다.
그림으로 표현하면 아래와 같습니다.
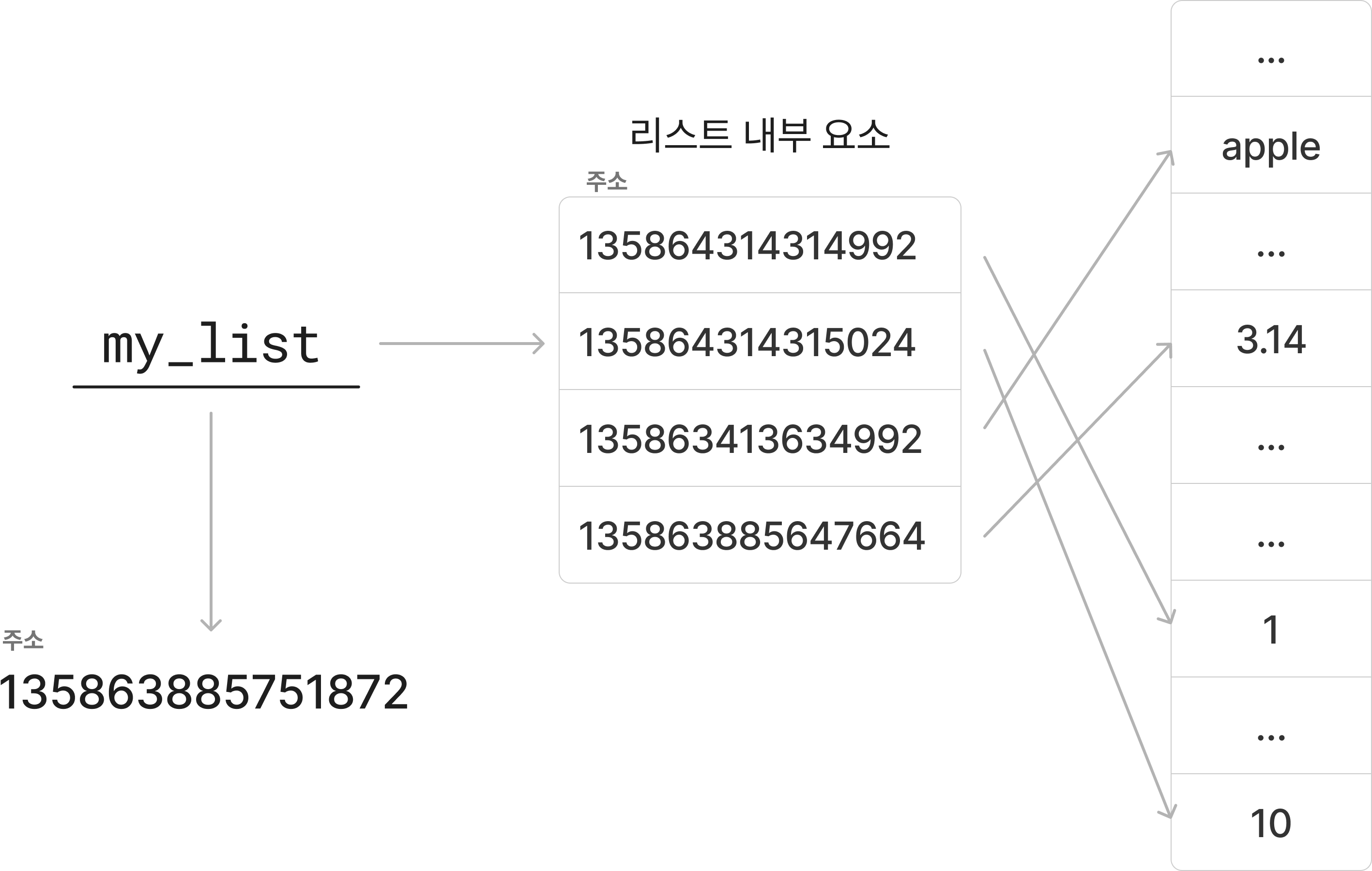
my_list는 각 요소에 대한 참조를 저장하고, 그 참조를 통해 실제 메모리 위치의 객체에 접근합니다. 리스트의 데이터는 실제로는 평면적인 선형 구조이지만, 마치 트리 형태로 데이터를 가리키는 것처럼 보입니다.
이러한 구조를 시각화 해서 보여줄 수 있는 서비스가 있습니다. pythontutor에서 코드를 입력하면 해당 코드의 메모리 구조를 시각화하여 보여줍니다. 실행할 때 에디터 창 아래 있는 옵션 값 중 중간에 있는 render all objects on the heap을 체크하면 모든 객체가 어디에 저장되어 있는지 확인할 수 있습니다. 실행을 하면 next 버튼을 누르면서 한 단계씩 진행하면서 메모리 구조를 확인할 수 있습니다.
l = [10, 'hello', [1, 2]]l = [10, 'hello', [1, 2]]이 코드에 실행 결과입니다.
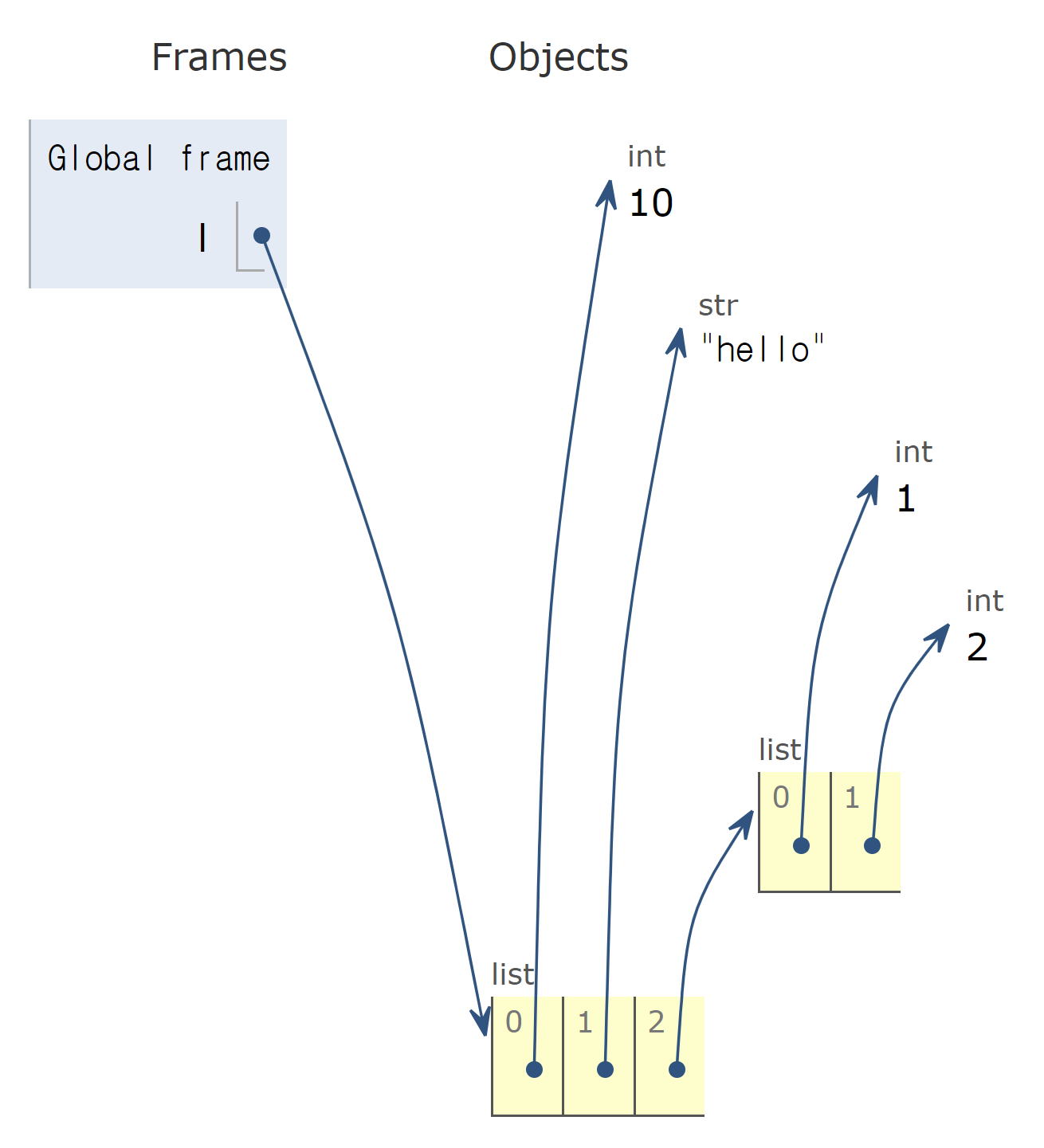
왜 이름이 리스트인가요?
자료구조에서 Array는 메모리가 연속적이고 길이가 고정인 반면, List는 메모리가 연속적이지 않고 길이가 가변적입니다. 파이썬의 리스트는 자료구조로 보면 Array에 가깝지만(동적 배열, dynamic array), 이름이 List인 이유는 귀도 반 로섬이 파이썬을 만들 때 ABC 언어에서 영감을 받았기 때문일 수 있습니다. ABC 언어에서는 이와 유사한 자료구조를 "리스트"라고 불렀습니다. 또한 "리스트"라는 용어가 일반적으로 "항목의 집합"이라는 개념을 잘 표현한다고 판단했을 수 있습니다. 정확한 이유는 알 수 없지만, 이는 흥미로운 고찰 주제입니다.
3.1.2 다른 언어에서의 메모리구조
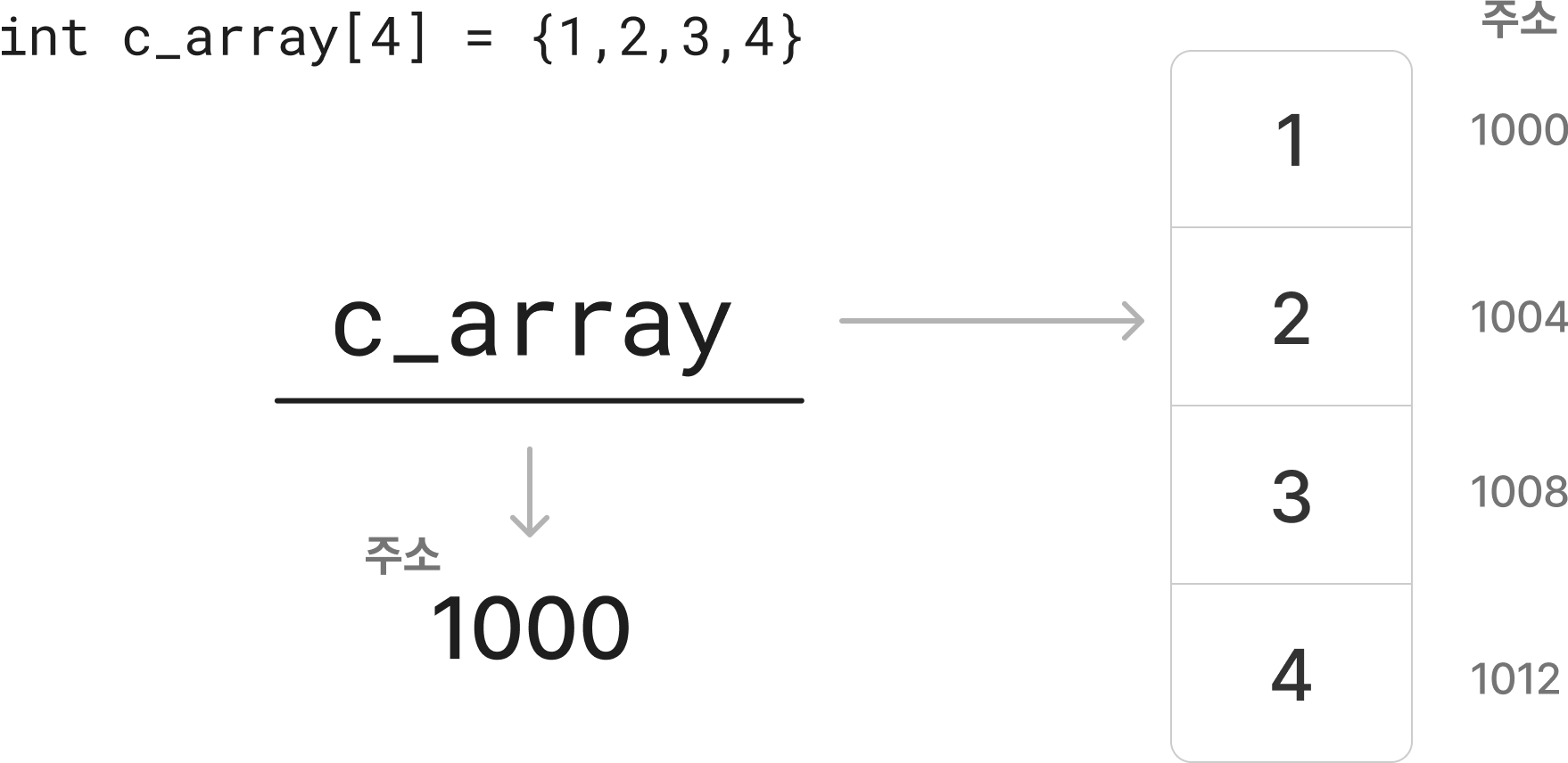
C언어에서의 배열은 메모리 상에서 연속적인 주소 공간에 직접 값을 저장합니다. 예를 들어, c_array라는 변수를 선언하면 1000이라는 특정한 위치를 가리키게 되고, 이 위치로부터 연속된 4개의 정수값이 저장됩니다. 이 변수에는 정수값만 담을 수 있습니다.
여기서 중요한 점은 데이터를 다루는 방식이 언어마다 다르다는 것입니다. 따라서 한 언어에서 이해한 개념을 그대로 다른 언어에 적용해서는 안 됩니다.
3.1.3 메모리 효율성과 성능
파이썬 리스트 메모리 구조의 장점은 다양한 데이터 타입의 원소를 동일한 리스트에 저장할 수 있고, 동적으로 크기를 조절할 수 있다는 것입니다. 하지만 이 구조에는 몇 가지 트레이드오프가 있습니다.
-
참조 저장을 위한 추가 메모리: 각 요소에 대한 참조를 저장하기 위해 추가적인 메모리가 필요합니다.
-
간접 접근으로 인한 성능 영향: 데이터에 접근할 때 참조를 통해 간접적으로 접근해야 하므로, 직접 값을 저장하는 방식에 비해 약간의 성능 저하가 있을 수 있습니다.
-
객체 오버헤드: 파이썬에서 모든 것이 객체이기 때문에, 작은 데이터(예: 정수)도 객체로 저장되어 추가적인 메모리를 사용합니다.
-
캐시 효율성: 리스트의 참조는 연속적으로 저장되지만, 실제 데이터는 메모리의 여러 곳에 분산되어 있을 수 있습니다. 이로 인해 캐시의 지역성(cache locality)이 떨어질 수 있으며, 대량의 데이터를 처리할 때 성능에 영향을 줄 수 있습니다.
이러한 특성들은 파이썬 리스트의 유연성과 편의성을 위한 트레이드오프로 볼 수 있습니다. 대부분의 일반적인 사용에서는 이러한 차이가 크게 문제되지 않지만, 고성능 컴퓨팅이나 대규모 데이터 처리 시에는 고려해야 할 사항입니다.
트레이드 오프(trade-off)
어떤 것을 얻기 위해 다른 것을 포기하는 것을 트레이드 오프라고 합니다. 예를 들어, 아이스크림을 더 많이 먹으면 행복감은 증가하지만 체중도 늘어날 수 있습니다. 여기서 '행복감'과 '체중 증가' 사이의 선택이 트레이드 오프입니다.
3.2 접근 시간
3.2.1 인덱스를 통한 접근 (Indexing)
리스트의 특정 인덱스에 위치한 요소에 접근하는 시간 복잡도는 O(1)입니다. 리스트는 내부적으로 배열 형태로 참조들을 저장하고 있어, 시작 주소에서 인덱스에 해당하는 오프셋(offset)만큼 이동해 해당 위치에 접근할 수 있습니다.
예를 들어, my_list[3]로 리스트의 4번째 요소에 바로 접근할 수 있습니다. 이때 중요한 점은 리스트의 각 요소가 메모리상에 연속적으로 저장되는 것이 아니라, 각 요소의 참조가 연속적으로 저장된다는 것입니다. my_list[3]의 경우, 리스트의 시작 주소에서 4번째 위치에 저장된 참조를 찾아 해당 참조가 가리키는 메모리 위치의 실제 객체를 반환합니다.
3.2.2 슬라이싱 (Slicing)
슬라이싱 연산은 새로운 리스트 객체를 반환합니다. 이 과정에서 해당 범위의 요소에 대한 참조를 새 리스트로 복사하는 시간이 필요합니다.
리스트를 슬라이스해서 부분 리스트를 얻는 연산의 시간 복잡도는 O(k)입니다. 여기서 k는 슬라이스의 길이입니다.
예를 들어, my_list[2:5]는 3개의 요소를 가진 부분 리스트를 반환합니다. 이 3개 요소의 참조를 새 리스트로 복사하는 데 슬라이스한 길이만큼의 시간이 걸립니다.
주의할 점은, 슬라이싱은 얕은 복사(shallow copy)를 수행합니다. 즉, 새 리스트의 요소들은 원본 리스트의 요소들과 같은 객체를 참조합니다.
3.2.3 검색
리스트 내에서 특정 요소를 찾는 시간 복잡도는 O(n)입니다. 여기서 n은 리스트의 길이입니다.
예를 들어, 3 in my_list는 리스트 전체를 순차적으로 검색하여 3이 포함되어 있는지 확인합니다. 최악의 경우(찾는 요소가 리스트의 마지막에 있거나 리스트에 없는 경우) 리스트의 모든 요소를 검사해야 합니다.
정렬된 리스트의 경우 이진 검색을 사용하면 O(log n)의 시간 복잡도로 검색할 수 있지만, 파이썬의 기본 'in' 연산자는 항상 선형 검색을 수행합니다.
3.2.4 마지막 요소 접근
리스트의 끝에서 요소에 접근하는 것도 O(1)의 시간 복잡도를 가집니다.
예를 들어, my_list[-1]은 리스트의 마지막 요소에 바로 접근합니다. 파이썬 리스트는 인덱스가 음수일 경우 리스트의 끝에서부터 요소를 참조합니다.
이 연산이 O(1)인 이유는 파이썬이 리스트의 길이를 별도로 저장하고 있어, 마지막 요소의 위치를 즉시 계산할 수 있기 때문입니다. 따라서 리스트의 길이와 관계없이 항상 일정한 시간이 걸립니다.
3.2.5 요소의 삽입
요소를 마지막에 추가하는 것은 O(1)이지만 중간에 요소를 삽입하는 것은 O(n)의 시간 복잡도를 가집니다. 이는 삽입 위치 이후의 모든 요소를 한 칸씩 뒤로 이동시켜야 하기 때문입니다.
4. 리스트 메서드
리스트는 다양한 메서드를 제공하여, 데이터를 처리하거나 리스트를 관리하기 편리합니다. 이번 섹션에서는 주요 리스트 메서드를 살펴보겠습니다.
본격적으로 설명하기 전에 파이썬 내장 함수인 dir() 를 이용해서 어떤 메서드와 어떤 속성이 있는지 살펴보겠습니다.
# 출력
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__','__dir__', '__doc__','__eq__', '__format__', '...중략' , 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']# 출력
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__','__dir__', '__doc__','__eq__', '__format__', '...중략' , 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']4.1 append()
리스트의 끝에 값을 추가합니다.
4.2 clear()
리스트의 모든 항목을 삭제합니다.
4.3 copy()
리스트의 얕은 복사를 생성합니다. 즉, 동일한 값을 가진 새로운 리스트를 반환합니다.
여기서 copy를 하지 않으면 아래와 같은 결과가 출력됩니다.
슬라이싱으로 copy와 같은 효과를 발휘할 수 있습니다.
다만 아래와 같은 코드에서는 의도치 않은 코드의 수정이 일어날 수 있습니다.
이럴 경우 copy 모듈을 사용하여 깊은 복사를 통해 해결할 수 있습니다. 깊은 복사는 기존의 값의 모든 참조가 더 이상 이어지지 않는 것입니다. 즉, 이제 l과 ll은 무관합니다.
4.4 count()
특정 값이 리스트에 몇 번 포함되어 있는지 카운트합니다.
4.5 extend()
리스트에 다른 리스트나 순회 가능한(iterable) 항목들을 추가합니다.
들어가는 값이 이터러블한 객체이기때문에 아래와 같이 활용될 수도 있습니다.
4.6 index()
주어진 값을 찾아 해당 값의 위치(인덱스)를 반환합니다. str 메서드에서 index와 함께 다뤘던 find 메서드는 리스트에 없습니다.
4.7 insert()
주어진 위치에 값을 삽입합니다.
4.8 pop()
리스트의 특정 위치에 있는 값을 반환하고 해당 값을 리스트에서 삭제합니다.
값을 넣지 않을 경우 마지막에서 값을 뺍니다.
아래와 같이 사용되기도 합니다. 여기서 while 구문은 뒤에 리스트가 있을 경우 리스트 안에 값이 있는 동안 반복합니다. 두 예제를 모두 실행해보세요.
l = [1, 2, 3, 4, 5]
while l:
print(l.pop(0)) # 1, 2, 3, 4, 5l = [1, 2, 3, 4, 5]
while l:
print(l.pop(0)) # 1, 2, 3, 4, 54.9 remove()
리스트에서 첫 번째로 발견되는 주어진 값을 삭제합니다.
아래와 같이 모든 요소를 제거할 수 있습니다. 여기서 l.count(2)가 있는 동안 그 아래 들여쓰기 4칸된 코드를 반복하게 됩니다.
다만 위의 방식 보다는 아래 방식을 사용하시는 것을 권합니다.
4.10 reverse() 및 reversed()
4.10.1 reverse()
리스트의 항목들의 순서를 뒤집습니다. 이 메서드는 원래의 리스트를 변경하고, 아무것도 반환하지 않습니다(None을 반환).
4.10.2 reversed()
역순으로 새로운 이터러블 객체를 반환하는 내장 함수입니다. map이나 zip처럼 메모리 값만 반환하기에 아래 예제에서는 리스트로 형변환을 하였습니다. 원래의 리스트는 변경되지 않습니다.
4.11 sort() 및 sorted()
4.11.1 sort()
sort()는 리스트 자체를 정렬합니다. 이 메서드는 원래의 리스트를 변경하고, 아무것도 반환하지 않습니다(None을 반환).
4.11.2 sorted()
sorted()는 새로운 리스트를 반환하는 내장 함수입니다. 원래의 리스트는 변경되지 않습니다.